数据库使用的是sqlserver,jdk版本1.8,运行在springboot环境下 对比3种可用的方式
- 反复执行单条插入语句
- xml拼接sql
- 批处理执行
先说结论:少量插入请使用反复插入单条数据,方便。数量较多请使用批处理方式。(可以考虑以有需求的插入数据量20条左右为界吧,在我的测试和数据库环境下耗时都是百毫秒级的,方便最重要)。
无论何时都不用xml拼接sql的方式。
newid()是sqlserver生成uuid的函数,与本文内容无关
insert into tb_item values
(newid(),#{item.uniquecode},#{item.projectid},#{item.name},#{item.type},#{item.packageunique},
#{item.ispackage},#{item.factoryid},#{item.projectname},#{item.spec},#{item.length},#{item.weight},
#{item.material},#{item.setupposition},#{item.areaposition},#{item.bottomheight},#{item.topheight},
#{item.serialnumber},#{item.createtime}
mapper接口mapper 是 mybatis插件tk.mapper 的接口,与本文内容关系不大
public interface itemmapper extends mapper- {
int insertbybatch(list
- itemlist);
}
service类
@service
public class itemservice {
@autowired
private itemmapper itemmapper;
@autowired
private sqlsessionfactory sqlsessionfactory;
//批处理
@transactional
public void add(list- itemlist) {
sqlsession session = sqlsessionfactory.opensession(executortype.batch,false);
itemmapper mapper = session.getmapper(itemmapper.class);
for (int i = 0; i < itemlist.size(); i ) {
mapper.insertselective(itemlist.get(i));
if(i00==999){//每1000条提交一次防止内存溢出
session.commit();
session.clearcache();
}
}
session.commit();
session.clearcache();
}
//拼接sql
@transactional
public void add1(list
- itemlist) {
itemlist.insertbybatch(itemmapper::insertselective);
}
//循环插入
@transactional
public void add2(list
- itemlist) {
itemlist.foreach(itemmapper::insertselective);
}
}
测试类
@runwith(springrunner.class)
@springboottest(webenvironment = springboottest.webenvironment.random_port, classes = applicationboot.class)
public class itemservicetest {
@autowired
itemservice itemservice;
private list- itemlist = new arraylist<>();
//生成测试list
@before
public void createlist(){
string json ="{n"
" "areaposition": "test",n"
" "bottomheight": 5,n"
" "factoryid": "0",n"
" "length": 233.233,n"
" "material": "q345b",n"
" "name": "test",n"
" "package": false,n"
" "packageunique": "45f8a0ba0bf048839df85f32ebe5bb81",n"
" "projectid": "094b5eb5e0384bb1aaa822880a428b6d",n"
" "projectname": "项目_test1",n"
" "serialnumber": "1/2",n"
" "setupposition": "1b柱",n"
" "spec": "200x200x200",n"
" "topheight": 10,n"
" "type": "steel",n"
" "uniquecode": "12344312",n"
" "weight": 100n"
" }";
item test1 = json.parseobject(json,item.class);
test1.setcreatetime(new date());
for (int i = 0; i < 1000; i ) {//测试会修改此数量
itemlist.add(test1);
}
}
//批处理
@test
@transactional
public void tesinsert() {
itemservice.add(itemlist);
}
//拼接字符串
@test
@transactional
public void testinsert1(){
itemservice.add1(itemlist);
}
//循环插入
@test
@transactional
public void testinsert2(){
itemservice.add2(itemlist);
}
}
测试结果:
10条 25条数据插入经多次测试,波动性较大,但基本都在百毫秒级别
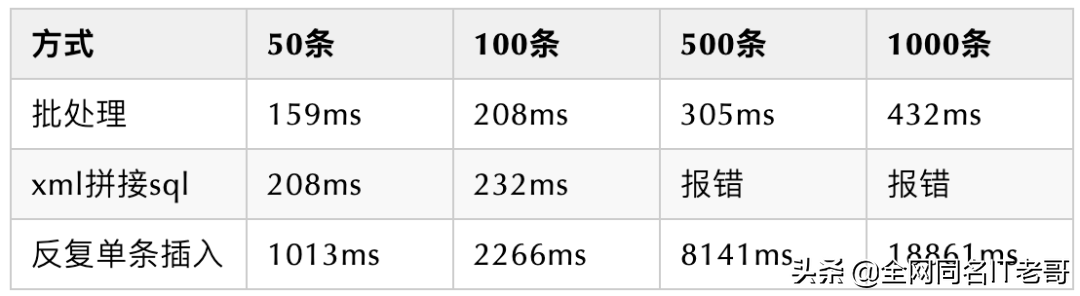
其中 拼接sql方式在插入500条和1000条时报错(似乎是因为sql语句过长,此条跟数据库类型有关,未做其他数据库的测试):com.microsoft.sqlserver.jdbc.sqlserverexception: 传入的表格格式数据流(tds)远程过程调用(rpc)协议流不正确,此rpc请求中提供了过多的参数,最多应为2100
可以发现
- 循环插入的时间复杂度是 o(n),并且常数c很大
- 拼接sql插入的时间复杂度(应该)是 o(logn),但是成功完成次数不多,不确定
- 批处理的效率的时间复杂度是 o(logn),并且常数c也比较小
循环插入单条数据虽然效率极低,但是代码量极少,在使用tk.mapper的插件情况下,仅需代码,:
@transactional
public void add1(list- itemlist) {
itemlist.foreach(itemmapper::insertselective);
}
因此,在需求插入数据数量不多的情况下肯定用它了。
xml拼接sql是最不推荐的方式,使用时有大段的xml和sql语句要写,很容易出错,工作效率很低。更关键点是,虽然效率尚可,但是真正需要效率的时候你挂了,要你何用?
批处理执行是有大数据量插入时推荐的做法,使用起来也比较方便。